

Source: http://www.3dnews.ru/storage/s
Introduction
Today, I would like to talk a little more about the SMART technology mentioned in the previous article on the criteria for choosing a hard drive, as well as find out the issue of the appearance of bad sectors when checking the surface with special programs and exhausting the reserve surface for their reassignment – a question raised on the forum from the last article.
To begin with, as always, a brief historical digression. The reliability of a hard drive (and any storage device in general) is always of the utmost importance. And the point is by no means its cost, but the value of the information that it takes with it to another world, leaving life itself, and the loss of profit associated with downtime when hard drives fail, if we are talking about business users, even if the information remains. And it is quite natural that you want to know about such unpleasant moments in advance. Even ordinary reasoning at the household level suggests that monitoring the state of the device in operation can suggest such moments. It remains only to somehow implement this observation in the hard drive.
For the first time, the engineers of the blue giant (IBM, that is,) thought about this task. And in 1995, they proposed a technology that monitors several critical parameters of the drive, and makes attempts to predict its failure based on the data collected – Predictive Failure Analysis (PFA). The idea was picked up by Compaq, which later created its own technology – IntelliSafe. Seagate, Quantum and Conner also participated in the development of Compaq. The technology they created also monitored a number of disk performance characteristics, compared them with an acceptable value, and reported to the host system if there was a danger. This was a huge step forward, if not in increasing the reliability of hard drives, then at least in reducing the risk of information loss when using them. The first attempts were successful, and showed the need for further development of technology. The S.M.A.R.T (Self Monitoring Analysing and Reporting Technology) technology, based on IntelliSafe and PFA technologies, has already appeared in the association of all major hard drive manufacturers (by the way, PFA still exists as a set of technologies for monitoring and analyzing various subsystems of IBM servers, including including the disk subsystem, and the monitoring of the latter is based precisely on SMART technology).
So, SMART is a technology for internally evaluating the state of a disk, and a mechanism for predicting a possible failure of a hard disk. It is important to note that the technology, in principle, does not solve emerging problems (the main ones are shown in the figure below), it can only warn about a problem that has already arisen or is expected in the near future.
At the same time, it must also be said that the technology is not able to predict absolutely all possible problems, and this is logical: the output of electronics as a result of a power surge, damage to heads and surfaces as a result of an impact, etc. no technology can predict. Predictable are only those problems that are associated with the gradual deterioration of any characteristics, the uniform degradation of any components.
Stages of technology development
SMART technology has gone through three stages in its development. In the first generation, the observation of a small number of parameters was implemented. No independent actions of the drive were provided. The launch was carried out only by commands on the interface. There is no specification describing the standard completely, and, therefore, there was not and is not a clear destiny about which parameters should be controlled. Moreover, their definition and the determination of the permissible level of their reduction was entirely left to the manufacturers of hard drives (which is natural due to the fact that the manufacturer knows better what exactly should be controlled by his given hard drive, because all hard drives are too different). And the software, for this reason, written, as a rule, by third-party companies, was not universal, and could erroneously report an impending failure (the confusion arose due to the fact that different manufacturers stored the values of various parameters under the same identifier). There were a large number of complaints that the number of cases of detection of a pre-failure state is extremely small (peculiarities of human nature: you want to get everything at once, it somehow never occurred to anyone to complain about sudden disk failures before the introduction of SAMRT). The situation was aggravated by the fact that in most cases the minimum necessary requirements for the functioning of SMART were not met (we will talk about this later). Statistics show that the number of predicted failures was less than 20%. The technology at this stage was far from perfect, but it was a revolutionary step forward.
Not much is known about the second stage of SMART development – SMART II. Basically, the same problems were observed as with the first. Innovations were the possibility of a background check of the surface, performed automatically by the disk during idle times and error logging, the list of controlled parameters was expanded (again, depending on the model and manufacturer). Statistics show that the number of predictable failures has reached 50%.
The modern stage is represented by SMART III technology. We will dwell on it in more detail, try to understand in general terms how it works, what and why it is needed.
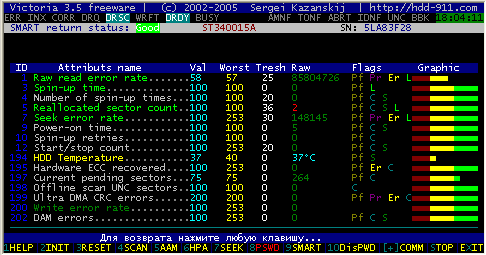
We already know that SMART monitors the main characteristics of the drive. These parameters are called attributes. The parameters required for monitoring are determined by the manufacturer. Each attribute has some value – Value. It usually ranges from 0 to 100 (although it can be up to 200 or 255), its value is the reliability of a particular attribute relative to some of its reference values (determined by the manufacturer). A high value indicates no change in this parameter or, depending on the value, its slow deterioration. A low value indicates rapid degradation or a possible failure soon, i.e. the higher the value of the Value attribute, the better. Some monitoring programs display the value of Raw or Raw Value – this is the value of the attribute in the internal format (which is also different for disks of different models and different manufacturers), in which it is stored in the drive. For a simple user, it is not very informative, the Value value calculated from it is of greater interest. For each attribute, the manufacturer determines the minimum possible value at which the drive’s failure-free operation is guaranteed – Threshold. If the attribute value is below the Threshold value, a malfunction or a complete failure is very likely. It remains only to add that attributes are critical and non-critical. If a critically important parameter goes beyond the Threshold, the actual value means failure, if a non-critical parameter goes beyond the allowed values, it indicates a problem, but the disk can still work (although, perhaps, with some deterioration in some characteristics: performance, for example).
The most frequently observed critical characteristics are: Raw Read Error Rate – The rate of errors when reading data from a disk, the origin of which is due to the disk hardware.
Spin Up Time – the time it takes for a pack of disks to spin up from rest to operating speed. When calculating the normalized value (Value), the practical time is compared with some reference value set at the factory. A non-deteriorating non-maximum value with Spin Up Retry Count Value = max (Raw equal to 0) does not mean anything bad. The difference in time from the reference can be caused by a number of reasons, for example, the power supply let us down.
Spin Up Retry Count – the number of retries to spin up disks to operating speed, if the first attempt was unsuccessful. A non-zero Raw value (respectively, a non-maximum Value) indicates problems in the mechanical part of the drive.
Seek Error Rate – error rate when positioning the block of heads. A high Raw value indicates the presence of problems, which may be damaged servos, excessive thermal expansion of disks, mechanical problems in the positioning unit, etc. A constantly high Value indicates that everything is fine.
Reallocated Sector Count – number of sector remapping operations. SMART in modern ones is able to analyze the sector for stability on the fly and, if it is recognized as a failure, reassign it. Below we will talk about this in more detail.
Of the non-critical, so to speak, informational attributes, the following are usually monitored:
Start/Stop Count is the total number of starts/stops of the spindle. The disk motor is guaranteed to be able to endure only a certain number of on / off. This value is chosen as Treshold. The first models of disks with a rotation speed of 7200 rpm had an unreliable engine, could only transfer a small number of them and quickly failed.
Power On Hours – the number of hours spent in the on state. Passport time between failures (MBTF) is selected as a threshold value for it. Given the usually quite improbable MBTF values, it is unlikely that the parameter will ever reach a critical threshold. But even in this case, the failure of the disk is completely optional.
Drive Power Cycle Count – the number of complete disk on/off cycles. This and the previous attribute can be used to estimate, for example, how much the disk was used before purchase.
Temperatue – simple and clear. The readings of the built-in temperature sensor are stored here. Temperature has a huge impact on disk life (even if it is within acceptable limits).
Current Pending Sector Count – the number of sectors that are candidates for replacement is stored here. They have not yet been identified as bad, but reading them is different from reading a stable sector, the so-called suspicious or unstable sectors.
Uncorrectable Sector Count – the number of errors when accessing the sector that have not been corrected. Possible causes may be mechanical failures or surface damage.
UDMA CRC Error Rate – the number of errors that occur when transmitting data over the external interface. Can be caused by low-quality cables, abnormal operating modes.
Write Error Rate – Shows the rate of errors that occur when writing to disk. It can serve as an indicator of the quality of the surface and the mechanics of the drive.
All errors and parameter changes that occur are recorded in the SMART logs. This possibility appeared already in SMART II. All parameters of the magazines – purpose, size, their number are determined by the manufacturer of the hard drive. At the moment, we are only interested in the fact of their presence. Without details. The information stored in the logs is used to analyze the state and make forecasts.
If you do not go into details, then the work of SMART is simple – during the operation of the drive, all errors and suspicious phenomena that occur are simply tracked, which are reflected in the corresponding attributes. In addition, starting with SMART II, many drives have self-diagnostic functions. SMART tests can be launched in two modes, off-line – the test is actually performed in the background, since the drive is ready to accept and execute a command at any time, and exclusive, in which when a command is received, the test execution ends.
Three types of self-diagnostic tests are documented: background data collection (Off-line collection), shortened test (Short Self-test), extended test (Extended Self-test). The last two can run both in the background and in exclusive modes. The set of tests included in them is not standardized.
The duration of their execution can be from seconds to minutes and hours. If you suddenly do not access the disk, and at the same time it makes sounds like during a workload, it just seems to be doing introspection. All data collected as a result of such tests will also be stored in logs and attributes.
Oh those bad sectors…
Now back to the issue of bad sectors, which started it all. SMART III has a feature that allows you to transparently reassign BAD sectors for the user. The mechanism works quite simply, with an unstable reading of a sector, or an error in reading it, SMART enters it into the list of unstable ones and increases their counter (Current Pending Sector Count). If the sector is read without problems during repeated access, it will be thrown out of this list. If not, then when given the opportunity – in the absence of access to the disk, the disk will start an independent check of the surface, primarily suspicious sectors. If the sector is recognized as bad, then it will be reassigned to the sector from the backup surface (respectively, RSC will increase). Such background remapping leads to the fact that on modern hard drives, bad sectors are almost never visible when checking the surface with service programs. At the same time, with a large number of bad sectors, their reassignment cannot continue indefinitely. The first limiter is obvious – this is the volume of the reserve surface. This is the case I had in mind. The second is not so obvious – the fact is that modern hard drives have two defect lists P-list (Primary, factory) and G-list (Growth, formed directly during operation). And with a large number of reassignments, it may turn out that there is no place in the G-list to record a new reassignment. This situation can be identified by a high rate of remapped sectors in SMART. In this case, all is not lost, but that is beyond the scope of this article.
So, using the SMART data, without even taking the disc to the workshop, you can pretty accurately say what is happening to it. There are various add-on technologies for SMART that allow you to determine the state of the disk even more accurately and almost reliably the cause of its failure. We will talk about these technologies in a separate article.
You need to know that purchasing a drive with SMART is not enough to be aware of all the problems that occur with the drive. The disk, of course, can monitor its condition without outside help, but it will not be able to warn itself in the event of an approaching danger. You need something that will allow you to issue a warning based on SMART data. (the usual chain is shown in the figure below).
Alternatively, BIOS is possible, which, when booting with the corresponding option enabled, checks the status of SMART drives. And if you want to constantly monitor the state of the disk, you need to use some kind of monitoring program. Then you can see the information in a detailed and convenient way.
SmartMonitor from HDD Speed running under DOS
SIGuiardian running from Windows
We will also talk about these programs in a separate article. This is what I meant when I said that at first the necessary requirements were not met when operating hard drives with SMART.
